The topic of empty homes attracts quite a lot of attention in England, given what seems to be a severe shortage of available housing. But surprisingly little is known about the reasons why homes may be standing empty, and how many are really available for a household to rent or buy.
The first point to cover is the overall rate of vacant homes (I’ll use ‘vacant’ from now on as that’s the term more commonly employed in official statistics). The OECD publishes the chart below as part of its Affordable Housing Database, showing the UK (actually England) with a very low rate of vacant homes, just 2.7% of the total. This is based on Council Tax data, which the OECD says is closest to the definition used in other member countries.
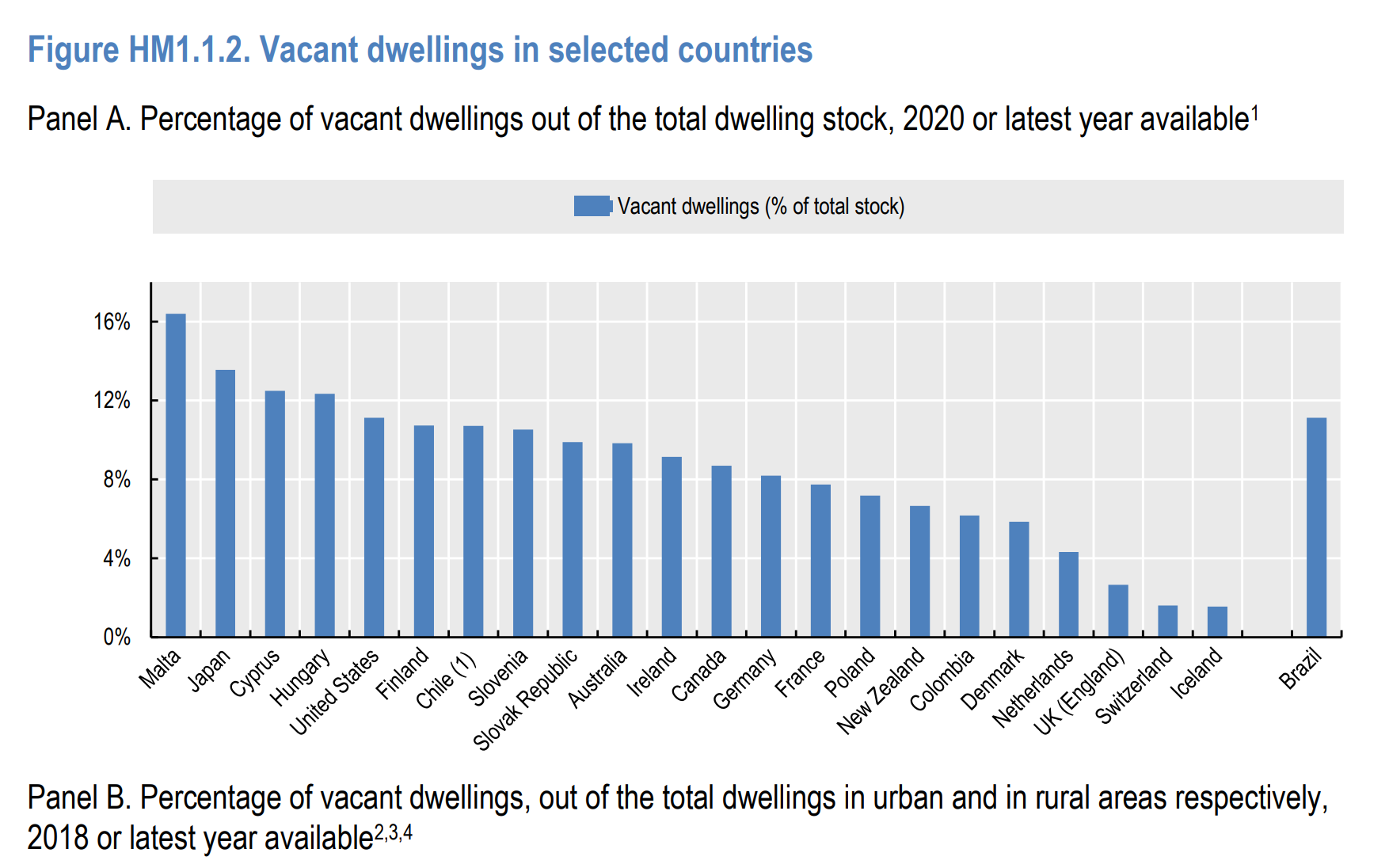
That may be so, but the UK/England figure is too low as a comprehensive estimate of vacant homes, because not every vacant property owner will go to the trouble of registering it as such. It’s not clear to what extent this same issue applies to other countries, but for now it is worth just noting the OECD average of 8.1% vacant homes (excluding Malta due to its size).
Instead of Council Tax data I’m going to use survey data in this post. The English Housing Survey (EHS) is the best available as it is set up for exactly this kind of question. It is still not perfect however, as it only covers England, it doesn’t count second homes in the dwellings total and the sample size is not huge. There is also the Census, but even in normal times its figures on vacant homes (sorry, ‘household spaces with no usual residents’) are not very clear, and the 2021 Census was taken at the distinctly abnormal mid-pandemic time of March 2021 so probably doesn’t tell us very much about vacant homes either side of the pandemic period.
For this post I have analysed EHS microdata, combining the 2017 and 2019 datasets to allow for a large enough sample for disaggregation, so I’ll refer to the resulting figures as a 2018 average. It’s worth noting that the coronavirus pandemic severely disrupted the EHS fieldwork and restricted its surveyors to assessing homes from the outside rather than carrying out physical inspections, so data on vacant homes for 2020 to 2022 is either not available at all or considered less reliable than the pre-pandemic period.
According to the EHS there were 1.1 million vacant homes in England in 2018, equivalent to 4.6% of the stock. This is higher than the 2.7% Council Tax figure reported by the OECD but is still lower than the figures reported by the OECD for every other country except the Netherlands, Switzerland and Iceland.
The overall rate of vacant homes in England hasn’t changed very much over the last few decades: it was 3.9% in 1996 (the earliest figure I can find, from the 1996 English House Condition Survey) and has hovered around 4.5% since 2009.
The figure should actually be lower than 4.6%, because the EHS doesn’t include second homes in its figure for the total dwelling stock. But the rate of second home ownership in England is low enough (around 4%, as discussed in a previous post) that I haven’t made any adjustment for it.
The EHS surveyors attempt to find out how long vacant homes have been vacant for, but are not always successful. In 2018 they reported 390,000 short-term vacants , dwellings that had been vacant for less than six months (1.6% of the total dwelling stock), and 430,000 that were long-term vacant for six months or more (1.8% of the stock). Another 1.2% had been vacant for some indeterminate amount of time.
The number of homes recorded as long-term vacant has increased slightly over the last decade (from around 400,000 in 2009 and 2011). One potential explanation comes from official statistics on Council Tax showing that the number of “Dwellings left empty by deceased persons” in England rose from 72,000 in 2012 to 122,000 in 2022, with statisticians attributing some of this increase to delays in probate. Now, whether these kinds of vacant homes are counted in the EHS as short-term or long-term doesn’t really matter – the point is they are being held off the market so aren’t available for someone else to move into, although if the delays get sorted their number should reduce again.
However, even short-term vacant homes may not actually be available to someone looking for a home, for example if they have already been sold or rented and are awaiting their new occupants moving in. The EHS says there are around 300,000 in England (slightly under half of which are awaiting owner occupants rather than tenants). This category of vacant homes is an important form of what are sometimes called ‘frictional’ vacancies – a baseline rate of empty properties that is always required to allow for mobility between homes, much like a healthy labour market requires a baseline rate of job vacancies.
There are other reasons why vacant homes may not be available for anyone to move into. Around 180,000 homes are estimated by the EHS to be vacant due to ongoing renovation or modernisation works, while around 20,000 (a very rough estimate, given the small number of survey cases involved) are considered derelict or are awaiting demolition.
There is a small amount of overlap between all these categories, but we can use them to construct a very rough estimate of how many vacant homes are not included in any of them and can therefore be considered available to rent or buy, at least in principle. According to my calculations there were around 630,000 ‘available’ homes in this sense in 2018 (2.6% of the total stock). How many of these are actually on the market is not something that the EHS data can tell us because the list of criteria I’ve used to calculate the figure is so narrow – not including, for example, those homes that are vacant and subject to probate.
So far I haven’t taken any account of the condition of vacant homes, except to the extent that EHS surveyors recorded them as derelict or undergoing modernisation. But there are other forms of poor housing conditions recorded by the EHS, which if they occur at a higher rate in vacant homes may indicate a need for investment before the home is put back on the market – or a home in such poor condition that there is very little demand for it.
The headline measure of dwelling condition used by the EHS is the Decent Homes Standard, which assesses homes on four criteria concerning health hazards, state of repair, thermal comfort and the condition and age of its facilities. 17% of occupied homes in 2018 fell below the Standard, but this figure rose to around 24% for short-term vacant homes and around 36% for those vacant for 6 months or more. 10% of occupied homes were assessed as containing at least one of the most serious (‘category 1’) health hazards, compared to around 11% of short-term vacant homes and around 22% of long-term vacants.
An estimated 4% of occupied homes had a damp problem in one more rooms in 2018, compared to 2% of short-term vacants and 6% of long-term vacants. Relatedly, the proportion of long-term vacant homes with poor energy efficiency was also much higher: 35% were assessed to be in band E or below, compared to 15% of short-term vacants and 16% of occupied homes.
The pattern here is fairly clear, and unsurprising: homes that are in poor condition are more likely to be long-term vacant. Perhaps this is as it should be, so long as they remain in that state: don’t forget that there are large numbers of homes in poor conditions – 2.4 million with serious health hazards, for example, and 800,000 with damp – that are occupied because their residents don’t have better choices available.
What effect does this analysis of conditions have on our overall figures? Again there are some overlaps between categories to deal with, and in total there are around 420,000 vacant homes that either fail the Decent Homes Standard, have a damp problem, have low (band E to G) energy efficiency or have substantial ‘basic’ repair costs (defined as more than £35 a square metre in line with EHS practice). This figure includes around a third of the vacant homes previously categorised as ‘available’, leaving around 410,000 homes (1.7% of the total stock) that are vacant, ‘available’ and not in a poor condition.
In summary, I think the key points are:
– The rate of vacant homes in England is higher than indicated by Council Tax data, but still lower than the rates reported by most other OECD countries;
– A significant proportion of vacant homes aren’t available for households to buy or rent, because they’re already awaiting occupants, they’re undergoing works, they’re held up in probate or some other reason;
– A further significant proportion are in notably poor condition, which may mean they haven’t been put on the market by their owners or they aren’t attracting any interested occupants.